social
diurnal
media
patterns
Cornell Tech
is the answer to the question:
If someone handed you $0.5B and half a freakin' island,
how would you revolutionize graduate education in the information age?

Extracting Diurnal Patterns of
Real World Activity from Social Media
By Nir Grinberg, Mor Naaman, Blake Shaw and Gilad Lotan
Motivation
Why Real-World Diurnal Patterns are interesting?
- Learn about real-world human behavior at unprecedented scale.
- Reason about platform differences.
- Model normal and abnormal activities at a city-level scale.
Data
-
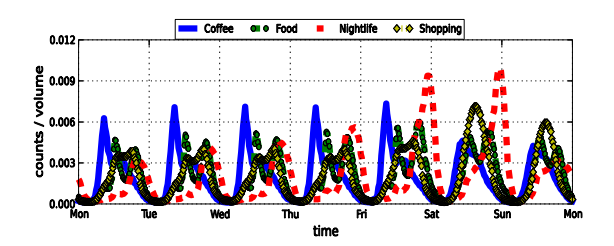
Foursquare:
- All checkins from 2011 and 2012, aggregated in 20 minutes bins by venue category and urban area.
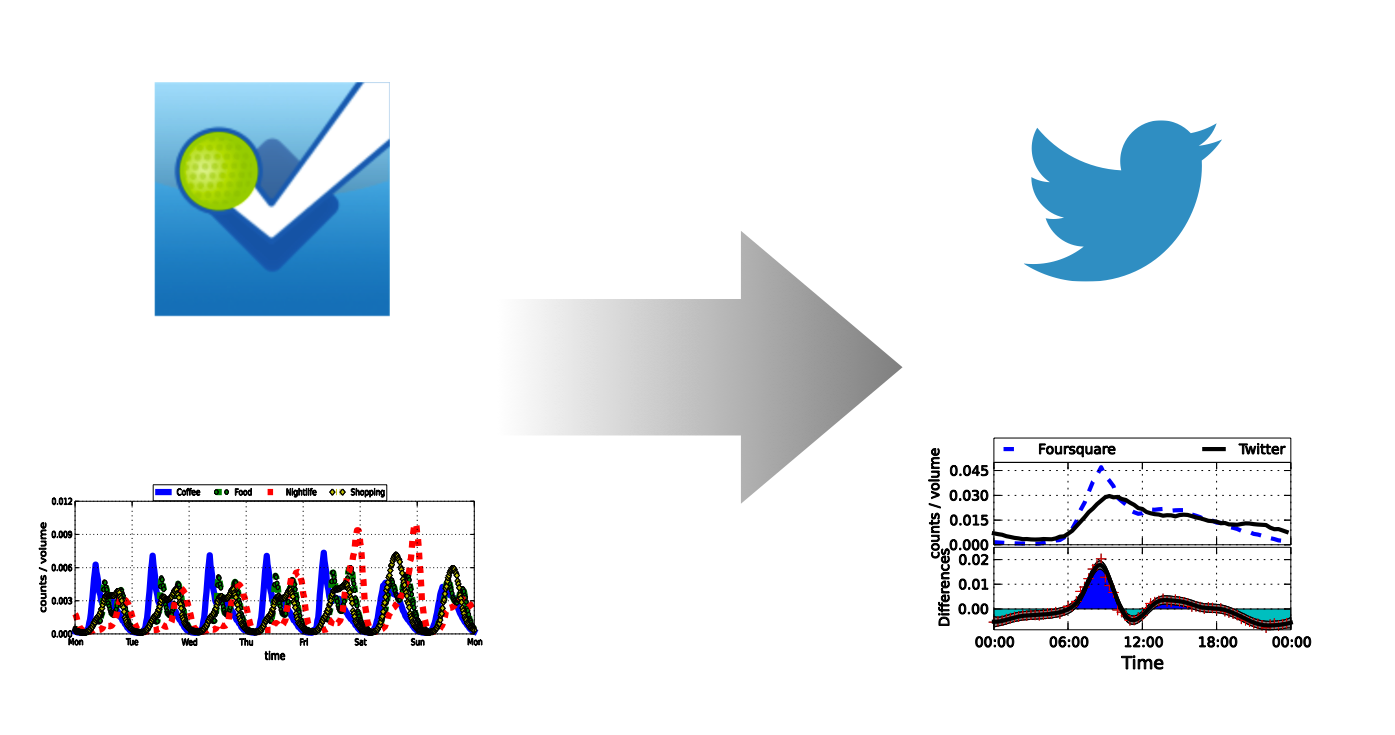
What are the equivalent
Twitter patterns
-
Twitter:
- Ten weeks (Sep-Nov 2012) of tweets from 7 of the biggest urban areas in the US.
- Location inferred from user hometown location.
- Co-occurrence patterns learned from 1 day of Twitter Firehose (>300M tweets).
?
Methods
Extracting indicative keywords of real-world activity
- Temporal Correlation
- Aggregated Pointwise Mutual Information*
- Context Pointwise Mutual Information*
- Hybrid: Context+Temporal
* method is available through our API
Methods (1)
Temporal Correlation
- Rank keywords based on time-series correlation with Foursquare signal.
-
More formally, let's define:
- $X^{4sq}_{cat}$ as the mean number of Foursquare check-ins over a week in all venues with primary category $cat$.
- $X^{t}_{K}$ as the mean number of tweets over a week that contain any of the terms in the set of keywords $K$.
- Then add keywords one by one according to the score:
Methods (2)
Aggregated Pointwise Mutual Information
- Given a small set of seed keywords for the category $\kappa$, ranks keywords based on $APMI$ score:
- Good at finding keywords co-occuring frequently with the seed list, but takes into account individual keyword popularity
- To reduce corpus specific "stopwords", we removed the top APMI terms occuring with a large random seed list
-
For instance, given 10 coffee terms (e.g. “coffee”, “starbucks”, etc.) and their hashtag form, $APMI$ found: “#frappuccino”, “iced” and “#barista”
Methods (3)
Context Pointwise Mutual Information
-
Given $\kappa$ as before, ranks keywords based on overlap between the keyword's context and seed list's context.
Where:
$C(w,n)$ is the context of the term $w$ obtained using the top $n$ terms by PMI, and
$C_{ref}(\kappa,n)$ is the concatenation of contexts in $\kappa$
Methods (3)
Context Pointwise Mutual Information (cont.)
- We found ContextPMI to be sensitive to small subsets of seed list terms that have similar context, but share very little with the rest of the seed list ===> Bootstrapping the seed list
-
Stoping criteria: $ContentPMI$ score > 500, that is, each term has to share an average of more than 5 terms with the seed's context.
-
For instance, for the same 10 coffee terms $ContextPMI$ found: “#cappuccino”, “macchiatos” and “#sbux” (shortened for Starbucks)
Methods (4)
Hybrid Approach
- Seeks to take advantage of the good semantic properties of $ContextPMI$ while retaining good temporal resemblance to the target Foursquare pattern.
- The Hybrid score is the ContextPMI score for terms that improve the overall correlation, otherwise 0.
Results
How well did our methods do?
- Evaluation:
Temporal Similarity, Quality, Quantity and Robustness
- Discuss platform differences
- Case study: Hurricane Sandy
Evaluation
Temporal Similarity
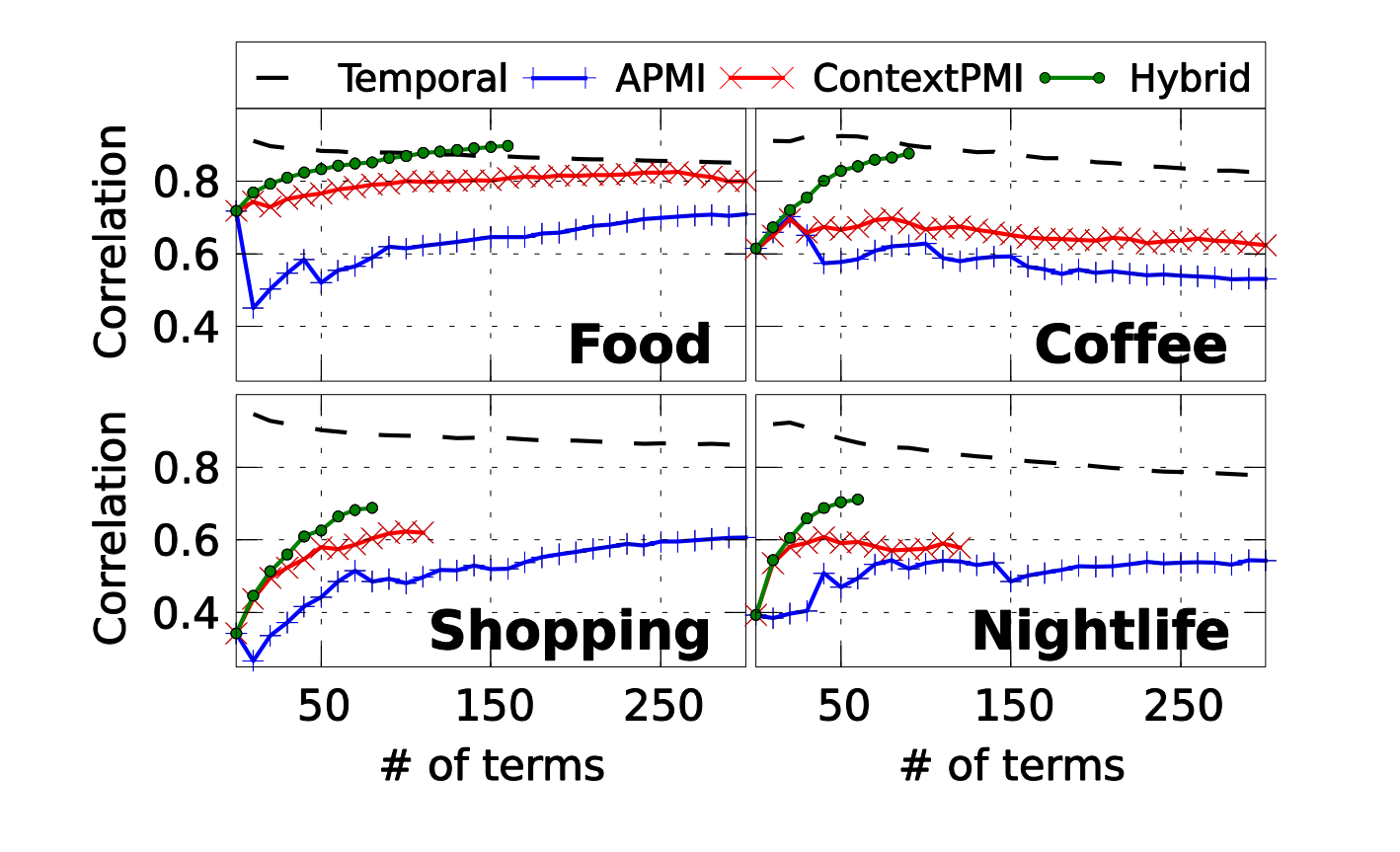
Evaluation
Manually Labeled Top Terms
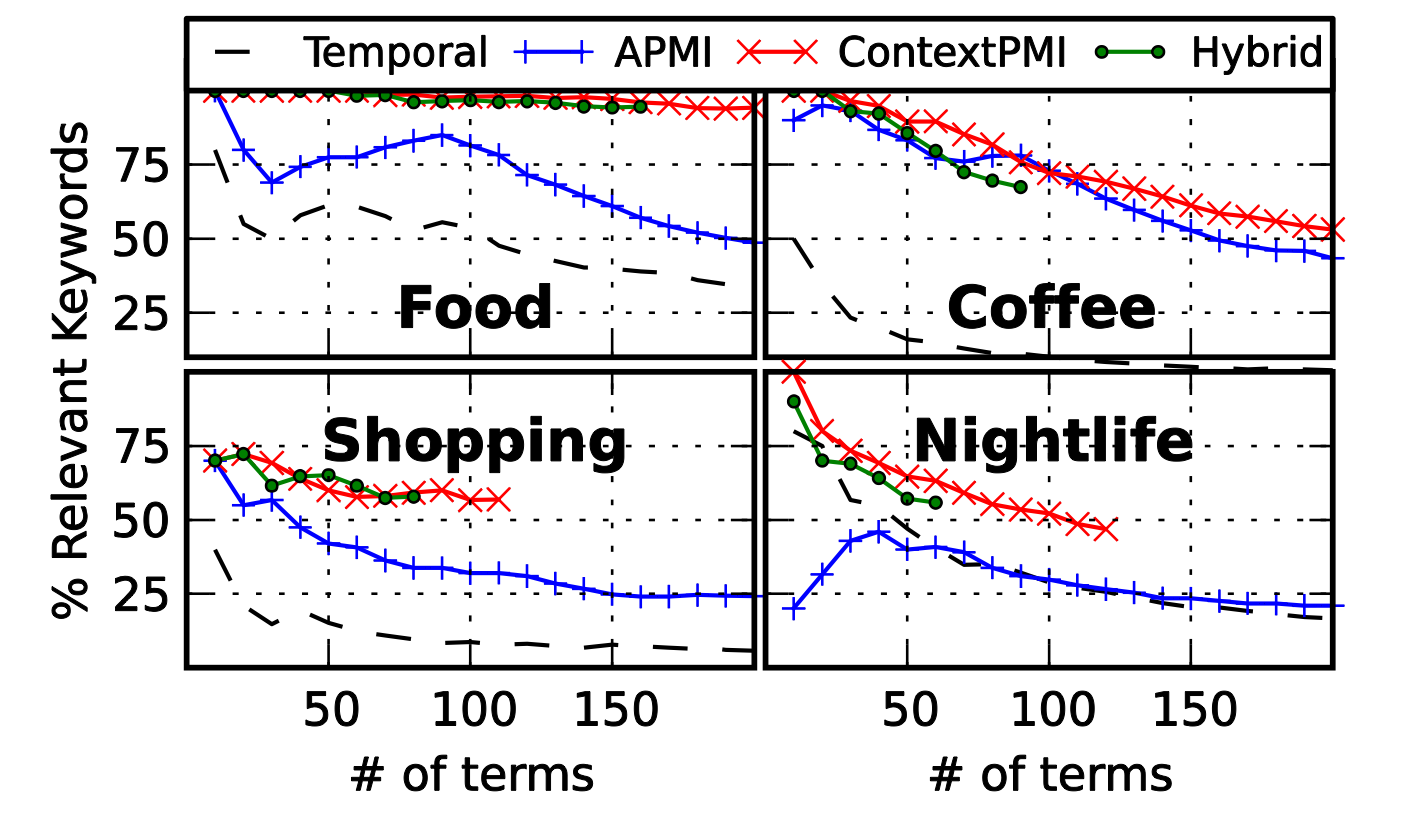
Evaluation
Quality vs. Quantity
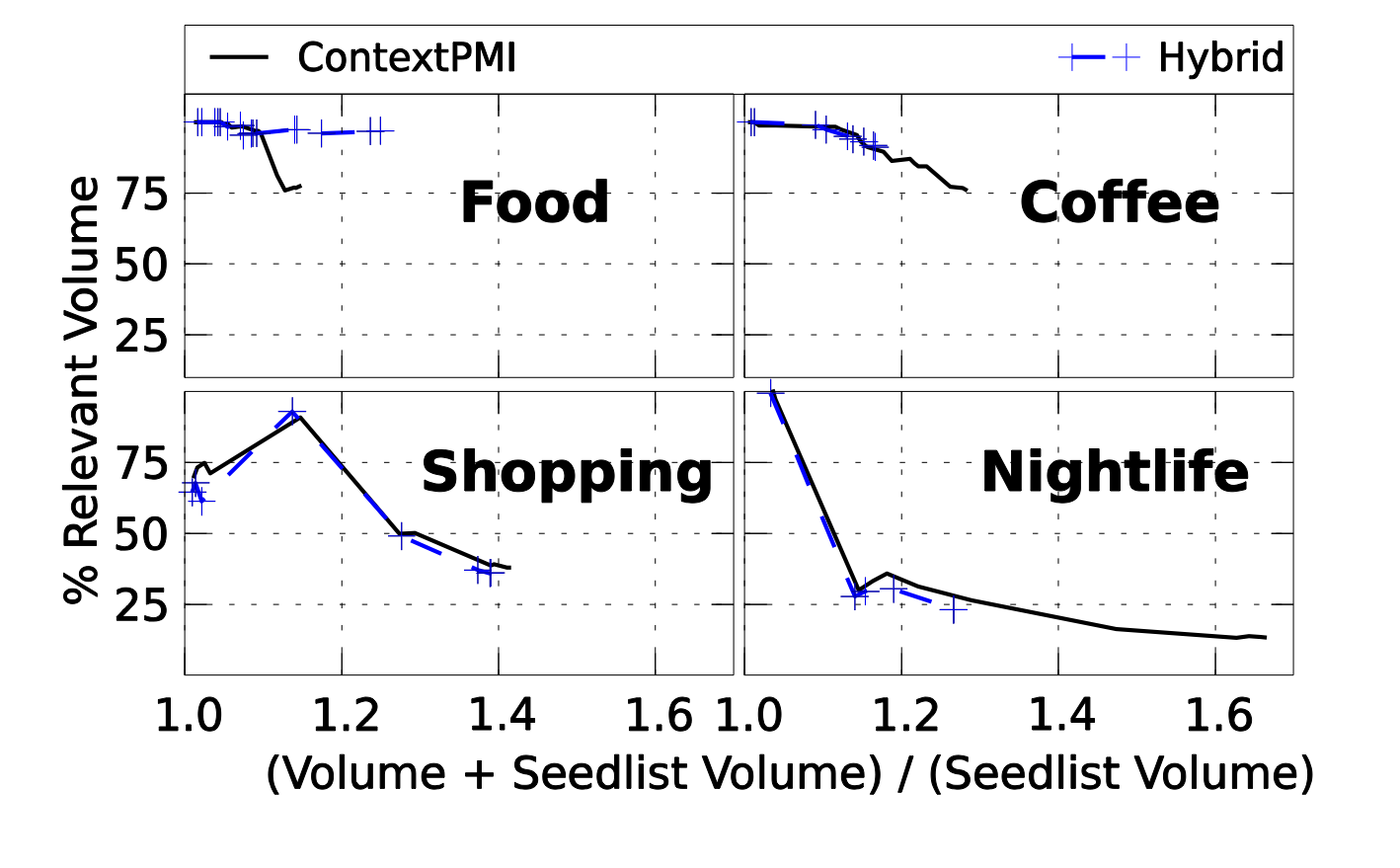
Evaluation
Robustness
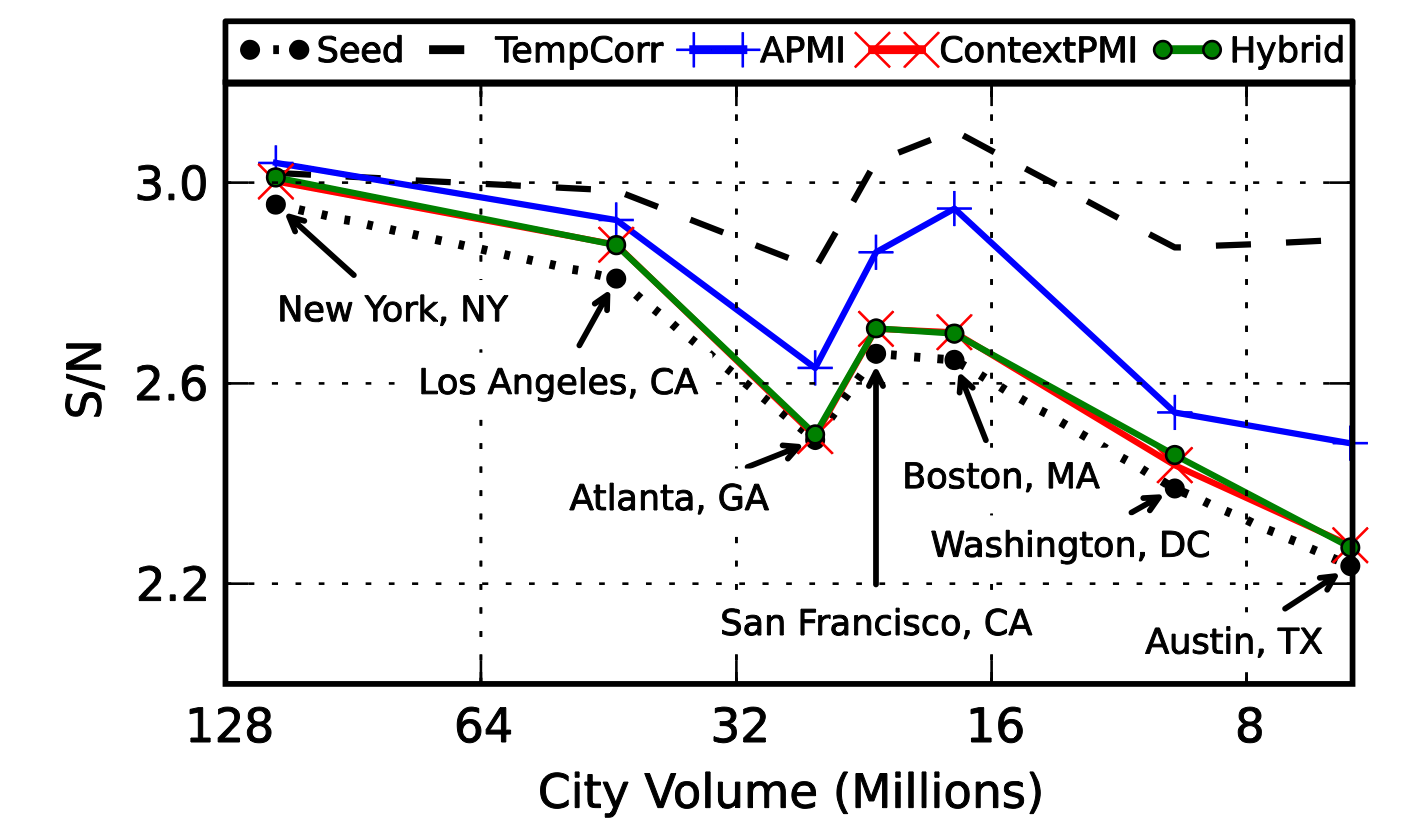
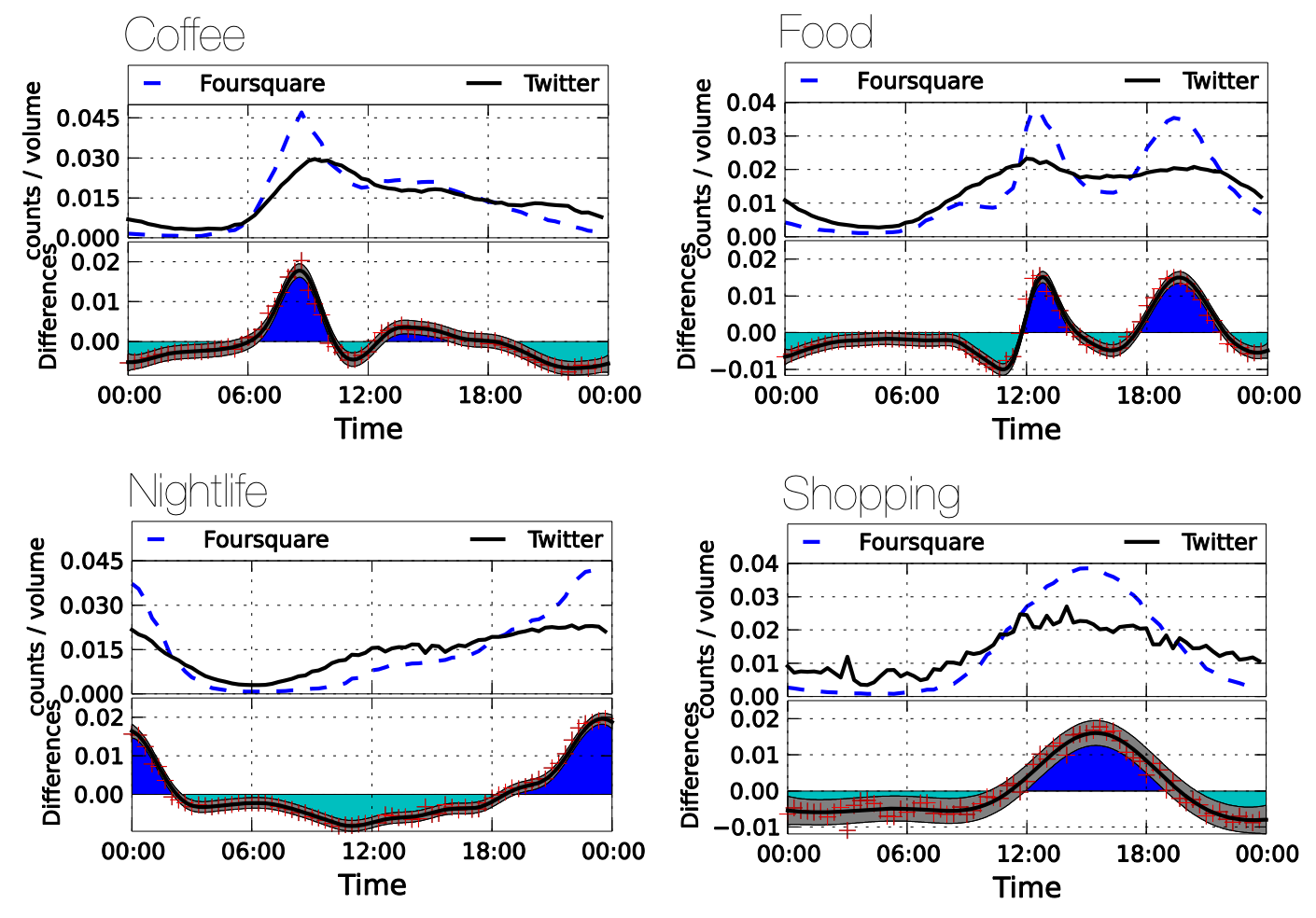
Platform Differences
(Normal Conditions)
This is nice, but it could all be just...

(From the New Yorker, January 31, 1977, Illustration by Dana Fradon)
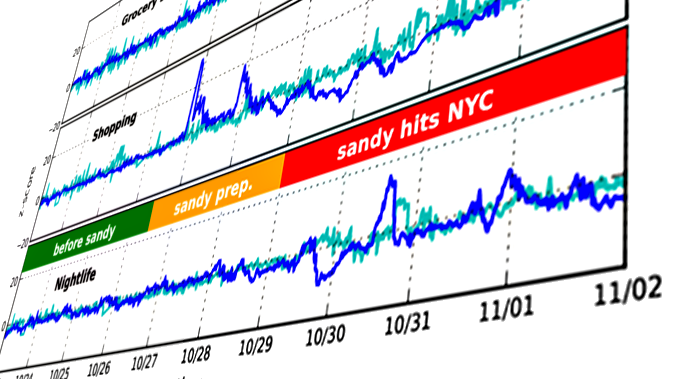
Pattern Disruption
Hurricane Sandy in NYC
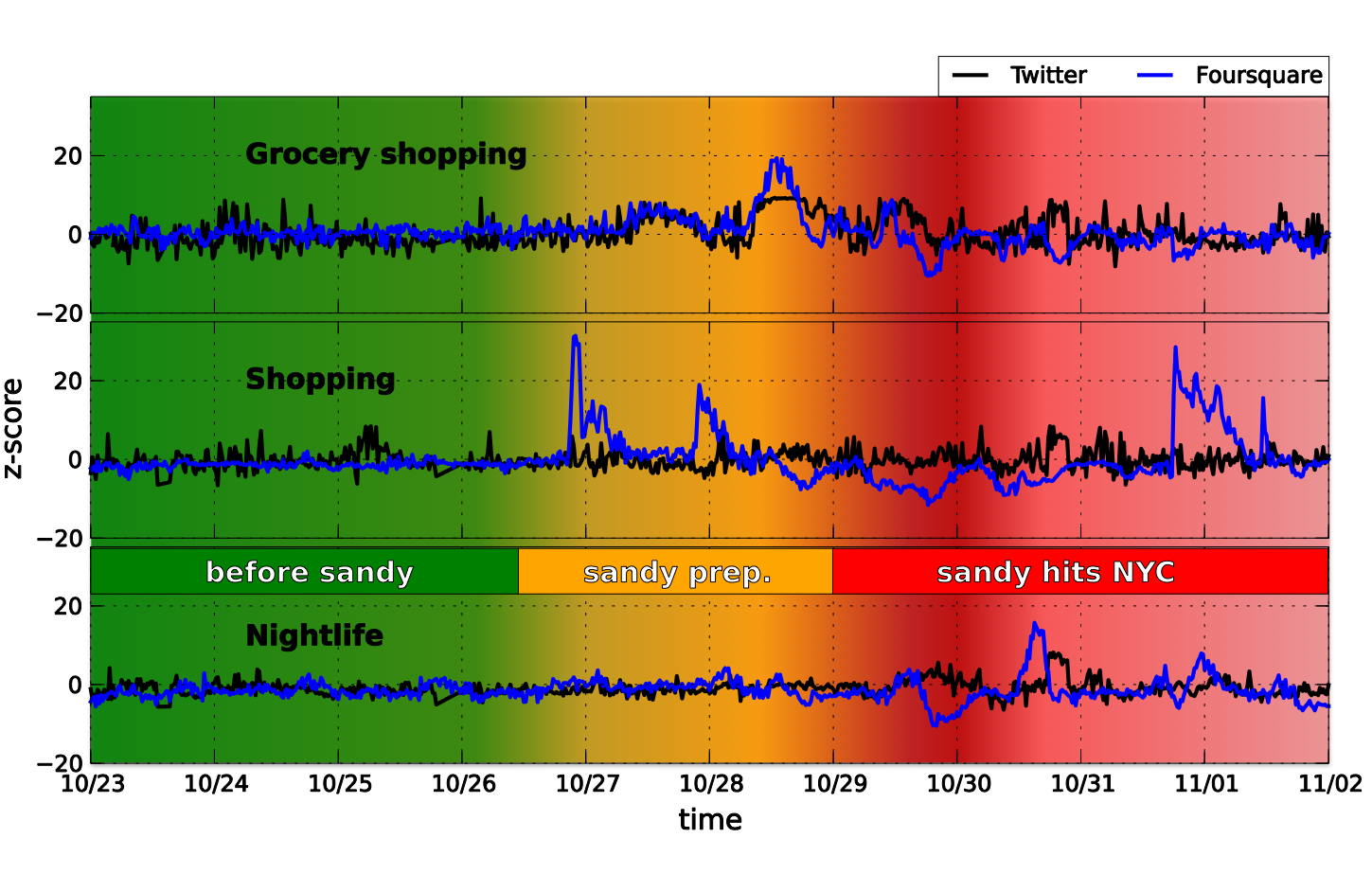
CityBeat
Conclusions & Discussion
What did we learn here?
- Developed keyword expansion methods for detecting real-world activities.
- Diurnal patterns in Foursquare closely resemble patterns on Twitter, with Twitter activity more spread around the peak of Foursquare activity.
- Our methods can be used to detect normal and abnormal conditions of activity.
- Mechanisms behind human behavior?
Other Projects
Work in Progress...
- Posters' behavior around contribution
- What language features make your read more?
- Behavioral changes in interacting with search results.